YOLO is an object detection algorithm using convolutional neural networks. It means “You only look once”. The reason is that the algorithm can detect things very quickly and in one go.
The reason why the YOLO algorithm is faster than other algorithms is that it passes the entire image through a neural network at once.
YOLO algorithm surrounds the objects it detects in images with a bounding box.
YOLO splits the input image into ((NxN)) grids. These grids can be 5×5,9×9,17×17….
Each grids considers whether there is an object in it and if it thinks the object exists, and whether the central point is in its own region.
A grid that decides that an object has a center point should find the class, height, and width of that object and draw a bounding box around that object.
Multiple grids may think that the object is within itself. In this case, unnecessary bounding boxes appear on the screen. All surrounding boxes have a confidence score. The non-max Suppression algorithm draws the highest confidence value from the bounding boxes drawn for the detected objects on the image to the screen.
In the graphs below, we can see the object detection performance of YOLO and some other algorithms for the MS COCO dataset.
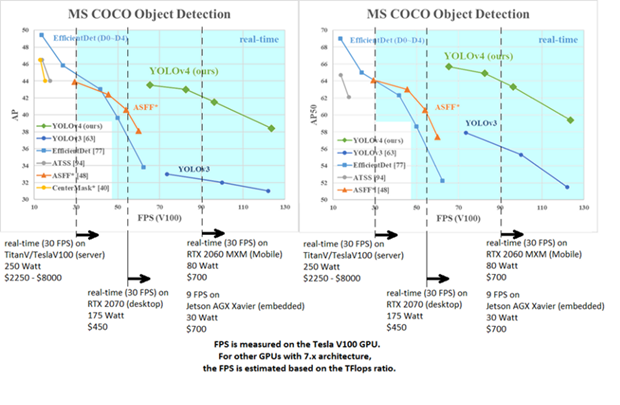
Given the case when the number of classifiers is equal, as shown in the graphics, YOLOv4 has almost 3 times the difference compared to its competitors.
The hardware and units in which the YOLO algorithm is used are also very important. When comparing in terms of performance and fps, for example: there is a huge difference between the cv2.dnn.DNN_BACKEND_CUDA module that comes with the OpenCV package and the darknet cuda that we build with our graphics card.
In order to use more original and faster templates, we always need to use our own darknet and cuda.
If we consider the possibility that we will have much better hardware in the future, yolo and similar algorithms will be even more important in many parts of our lives.